从总线上LS操作数
asm volatile("vsetvli %0, %1, e32, m1, ta, ma" : "=r"(vl) : "r"(avl));
asm volatile("vle32.v v1, (%0)" ::"r"((CHDATA->i_prompt)));
asm volatile("vle32.v v2, (%0)" ::"r"((CHDATA->q_prompt)));
asm volatile("vse32.v v1, (%0)" ::"r"(i_sum));
asm volatile("vse32.v v2, (%0)" ::"r"(q_sum));
9301 cyc vs. 10000 cyc
优化移位
CHDATA->ms_sign[ch] = CHDATA->ms_sign[ch] << 1;
9184 cyc vs. 10000 cyc
带条件或
if (q_sum[ch] < 0)
CHDATA->ms_sign[ch] = CHDATA->ms_sign[ch] | 0x1;
9109 cyc vs. 10000 cyc
实际上Spatz并不支持真正的掩码操作
数学计算
dcarr[ch] = (i_sum[ch] * -1024) * sign(q_sum[ch]) / rss_temp1[ch];
向量化vss
9053 cyc vs. 10000 cyc or10494(带abs)
实验结果
IPU = 4 同时8个环路滤波
1627 cyc VS. 10052 cyc
3260 cys VS. 14657 cyc
2,016 cys VS. 10052 cyc
3,625 cys VS. 20,053 cyc
6,911 cys VS. 39934 cyc
1392 + 144*3 bytes VS. + 3172 + 172 *3bytes
vrf相当于一个数据暂存区,从而不用频繁的发送寄存器与内存之间的数据交换,节省了运算的时钟周期
if ls消耗时钟周期数
1340 总线read
639 总线write
99 总线read
201 总线write
1238 总线read
608 总线write
102 总线read
210 总线write
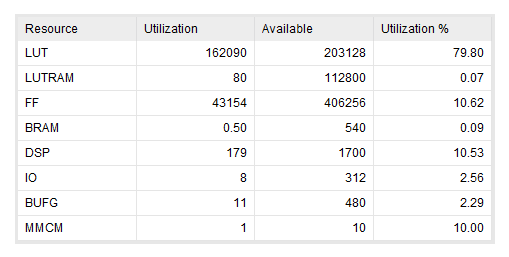
Vivado综合@2022.2
VREGS = 32 * 256bits
cv32e40p

4ipu 0fpu
0.063
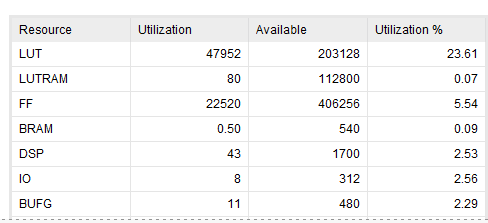
no spatz
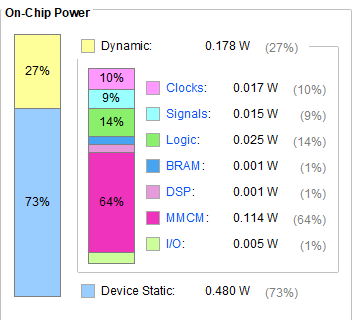
0.031W

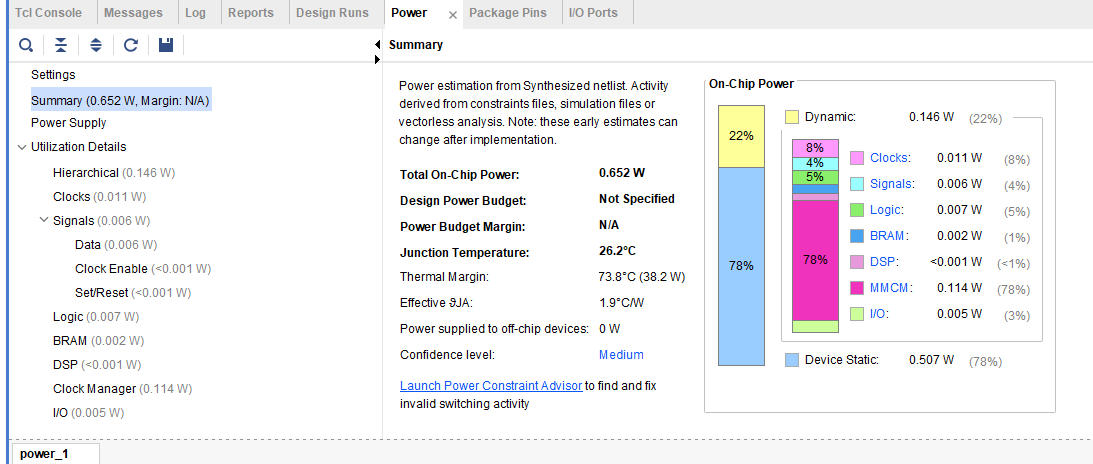
4IPU 4FPU
0.173
0.169